Loi de Moore, Scaling Laws et Endurance des IA : vers une nouvelle courbe exponentielle ?
Depuis des décennies, la technologie avance à une vitesse folle. Et une grande partie de cette accélération s’explique par un principe simple, presque prophétique : la loi de Moore.
Mais aujourd’hui, une autre dynamique est en train de prendre le relais – celle des scaling laws appliquées à l’intelligence artificielle. Et encore plus récemment, un nouvel indicateur fascinant fait surface : l’endurance des IA, qui semble, elle aussi, progresser de manière exponentielle.
Décortiquons tout ça.
Loi de Moore vs Scaling Laws : quelles différences ?
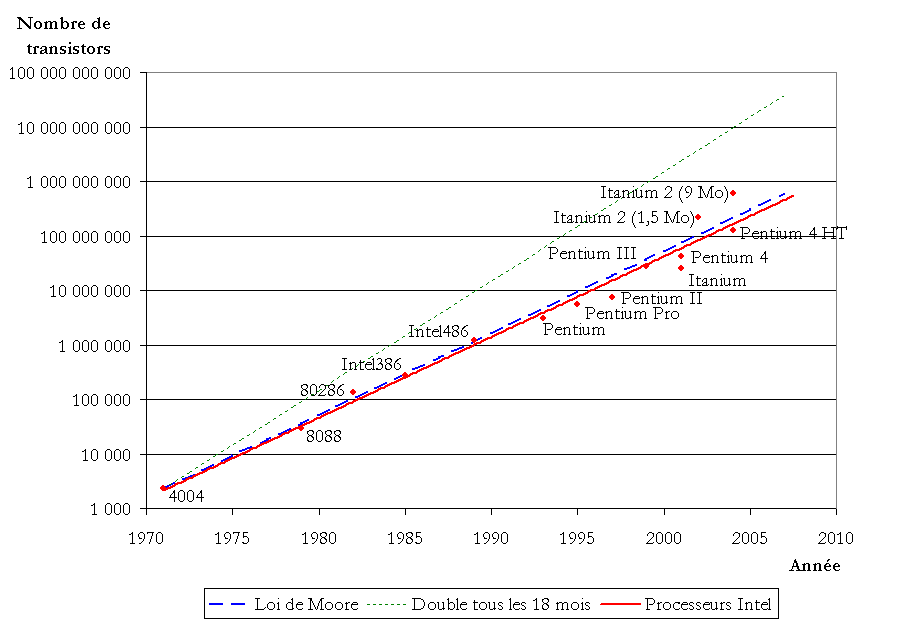
La loi de Moore – une histoire de hardware
Formulée par Gordon Moore en 1965 (et révisée en 1975), cette loi prédit que :
Le nombre de transistors sur une puce électronique double tous les deux ans.
Traduction : la puissance de calcul augmente rapidement, alors que les coûts baissent. Cette croissance exponentielle a permis l’évolution fulgurante des ordinateurs, du mainframe à l’ordinateur portable, puis au smartphone dans notre poche.
Mais ces dernières années, cette progression ralentit. On s’approche des limites physiques : miniaturisation extrême, consommation d’énergie, surchauffe… Difficile de continuer à tout doubler.
Les Scaling Laws – le monde du software
C’est là qu’entrent en jeu les scaling laws de l’IA, observées notamment par OpenAI, DeepMind et Anthropic. Ces lois montrent que :
Les performances des modèles d’IA s’améliorent de manière prévisible lorsqu’on augmente la taille du modèle, la quantité de données, et la puissance de calcul utilisée pour l’entraîner.
Autrement dit, si on scale bien – plus de paramètres, plus de data, plus de compute – on obtient des modèles plus intelligents, plus cohérents, plus performants.
C’est ainsi qu’on est passé de GPT-2 à GPT-3, puis à GPT-4… avec des gains significatifs à chaque étape.
Le plafond des scaling laws classiques
Mais en 2024, plusieurs signaux indiquent que cette stratégie atteint ses limites :
Les modèles comme GPT-4 ou Claude 3 sont déjà énormes. Les pousser encore plus loin devient extrêmement coûteux.
Le coût énergétique et matériel de l’entraînement devient insoutenable : des centaines de millions, voire des milliards de dollars par modèle.
Et surtout, on observe des rendements décroissants : doubler la taille d’un modèle n’apporte plus le double de performance, mais parfois des gains marginaux.
OpenAI, DeepMind, Anthropic… tous les acteurs majeurs le reconnaissent à demi-mot :
La croissance linéaire par le scaling pur et dur n’est plus suffisante.
On arrive donc à un tournant. Pour aller plus loin, il faut changer d’approche. Et c’est justement ce que propose l’étude du METR : passer de la performance brute à une nouvelle dimension plus stratégique…
👉 L’endurance.
Une nouvelle métrique : l’endurance des IA
Jusqu’ici, on mesurait surtout la puissance d’un modèle d’IA par sa précision sur une tâche donnée (ex. : est-ce qu’il peut coder une fonction, répondre à une question, traduire un texte…).
Mais une récente étude du METR (Model Evaluation and Technical Reports) introduit un nouveau type de benchmark :
Combien de temps une IA peut-elle travailler sur une tâche complexe avant d’échouer ?
En d’autres mots : on ne regarde plus seulement si l’IA peut sprint, mais si elle peut tenir un marathon.
Ce que l’étude a révélé
Les chercheurs ont testé plusieurs modèles – de GPT-2 (2019) à Claude 3.5 Sonnet (2025) – sur des tâches complexes, comme le raisonnement logique, le développement logiciel ou la cybersécurité.
Ils ont comparé les performances des IA à la durée que mettrait un humain qualifié à accomplir la même tâche.
Résultats :
En 2022, GPT-3 réussissait presque toutes les tâches de moins de 4 minutes, mais échouait dans plus de 90 % des cas sur des tâches de plus de 30 minutes.
En 2025, Claude 3.5 et GPT-4 peuvent tenir jusqu’à 1 heure de travail humain avec un taux de réussite élevé.
Et selon les projections, l’endurance des IA double tous les 7 mois.

Projections : à quoi pourrait ressembler le futur ?
Si la tendance continue :
2026 : tâches de 8h (une journée de travail)
2027 : projets de 2 à 3 jours
2028 : une semaine complète
2029 : projets d’un mois
2031 : capacité à gérer une année entière de travail, en autonomie
Et ce n’est pas tout. Sur des cas très spécialisés comme SWE-bench (une batterie de tests réels pour développeurs), l’endurance double tous les 3 mois. Autant dire que certaines dates pourraient arriver bien plus tôt que prévu.
Prudence et nuances
Évidemment, cette progression est moyenne. Elle varie selon les domaines, les types de tâches, et les modèles testés.
Des chercheurs comme Tamay Besiroglu soulignent que sur des disciplines très structurées (comme les échecs), les progrès sont plus lents et moins généralisables. D’autres rappellent qu’un taux de réussite de 50% n’est pas toujours exploitable en entreprise.
Enfin, certains évoquent le risque de rendements décroissants : il faudra peut-être beaucoup plus de puissance pour des gains de plus en plus faibles.
Cette étude ne dit pas que l’IA va vous remplacer demain matin. Mais elle montre une chose : les IA deviennent de plus en plus capables de gérer des tâches longues, complexes, et multi-étapes.
Conclusion
On pensait que la loi de Moore avait atteint ses limites. Mais les IA sont en train d’écrire une nouvelle page de l’histoire des exponentielles.
Et cette fois, ce n’est pas seulement la puissance qui augmente.
C’est l’endurance cognitive.